MapReduce 论文
Introduction
MR Lib一个抽象,简化计算的表达, 隐藏并行(parallelization), 错误容忍(fault-tolerance), 数据分布(data distribution) 和 负载均衡(load balance).
MR 灵感来自 Lisp 和其他许多函数式(functional)语言的 map 和 reduce.
Programming Model
Map: (k, v) —> list(k1, v1)
MR Lib 排序 Map 所产生的中间 k/v 对, 联合相同的 k 值的 k/v 的 v 生成新的 (k, list(v)).
Reduce: (k, list(v)) —> new list(v)
list(v) 通过迭代器方式传入 Reduce, 节省内存.
// 统计文档中单词频率
Example:
map(String key, String):
// key: document name
// value: document contentes
for each word w in vlaue:
EmitIntermediate(w, "1");
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v)
Emit(AsString(result))
Implementation
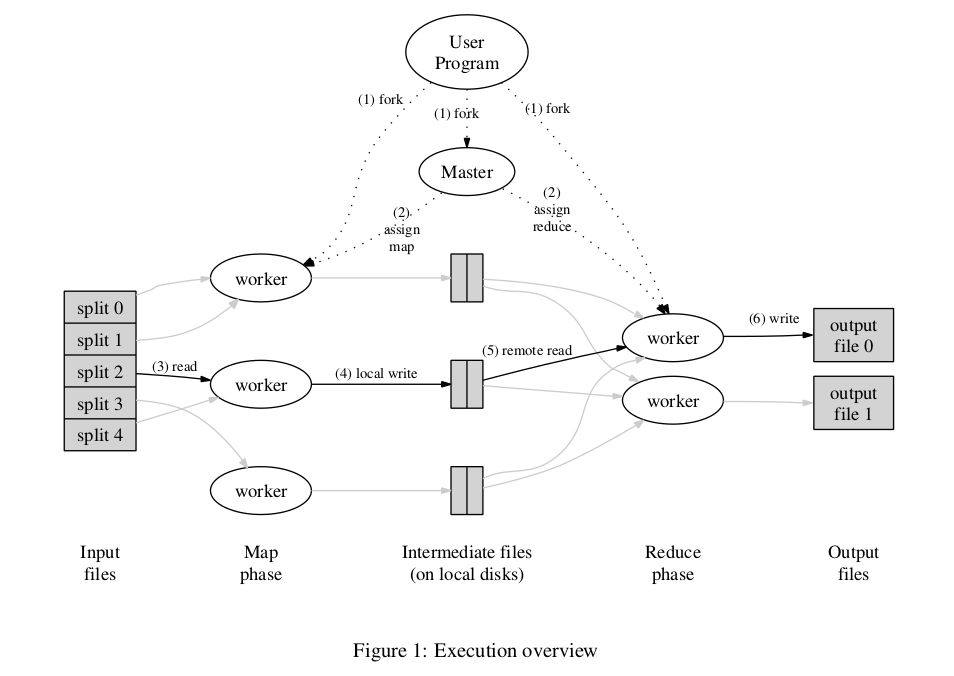
Execution Overview
- 输入文件切割成 M 个, 每个 64MB(可配置), 启动集群中拷贝的程序.
- 拷贝的程序中1个 master, 剩余为 worker. master 负责分配 Map 或 Reduce 任务给 idle worker. 有 M 个 Map 任务 和 R(可配置) 个 Reduce 任务.
- mao worker 负责读取被分配到的 Map 任务的对于的文件, 从输入文件解析出 key/value 当中用户定义的 Map function, 把产生的中间 k/v pairs 缓存在内存中.
- 定期的, 按照分区(partition)函数划分为 R 块写到本地磁盘. 并把这些数据的位置传给 master, master 负责转发给对应的 reduce worker.
- reduce worker 被 master 告知数据位置后, 用 RPC 调用读取数据, reduce worker 读取完所有的中间数据后, 排序数据以便按照相同 key 组织数据. 如果数据太大内存无法满足, 会使用外部排序
- reduce worker 遍历已排序的中间结果, 把 (k, list(v)) 当中用户定义的 Reduce function 的输入. Reduce function 的结果追加对应分区最终输出文件.
- 所有 map tasks 和 reduce tasks 完成后, master 唤醒用户程序(user program), 返回结果.
最终生成 R 个输出文件,这些文件可以用于另一个 MapReduce 调用.
Master Data Structures
- master 存储 map task 和 reduce task 的 state(idle, in-progress or completed) 和 no-idle state task 的worker 机器的标识(identity)
- master 是传递 map tasks 产生中间文件区域给 reduce tasks 的管道, 故存储了R 个中间文件区域的位置和大小为每个 map task.
Fault Tolerance
Worker Failure
master 定期 ping worker, 一定时间没有回应的 worker 标记为 failed.
worker 为 failed 后:
complete map task 重新设置为 idle state, 被调度到其他 worker 重新执行, 因为原来输出的中间文件已经不可以达的. 重新执行完成后, master 将通知所有正在执行的 reduce task(未读取到文件的) 新的文件位置并重新执行.(注意如果所有的reduce task 都已经获取到中间文件的话, 不需要从新执行)
complete reduce task 没有这个问题, 因为它输出文件存储在全局文件系统(GFS).
in-process map or reduce task 也被重新设置为 idle state.
MapReduce 可以容忍大范围的 worker faiilure, 并最终完成任务.
Master Failure
定期保存 master date structures 的检查点(checkpoint), master dies 可以重新从最新的检查点重启.
由于master 是单节点, 所以 master 失败, 那么计算就停止了.
Semantics in the Presence of Failures
如果用户定义的 map 和 reduce 是 deterministic, 那么整个分布式系统产生的结果和无错误顺序计算的结果是相同的.
我们依赖 map task 和 reduce task 原子提交输出保证上述熟悉:
in-process map task 输出写入 R 个临时的文件, map task 完成时, worker 这 R 个文件的名字发生给 master, 如果这个 map task 已经完成就忽略它, 否则 master 记录这 R 个文件的名字.
in-process reduce task 输出写入一个临时的文件, 当 reduce task 完成时, 原子重命名临时文件为最终文件, 如果有多个 worker 完成相同的 reduce task, 依赖底层文件系统保证文件重命名的原子性, 来保证最终文件是其中一个任务的结果.
Locality
为了节省网络带宽, master 根据输入文件的位置信息, 分配 map task 到包含对应输入文件的机器上运行, 当时失败时, 尝试输入文件备份的机器上运行(GFS 默认3个备份(replica)), 因此大部分任务读取本地文件不消耗带宽.
Task Granularity
理想情况 M 和 R 的大小应该比机器数量大的多, 这样每个 worker 执行许多不同的任务来改善动态负载均衡, 和快速恢复当 worker fail 时, 失败的 worker 上完成的 map tasks 可以分配给其他的机器上.
M 和 R 的限制: master 需要做 O(M + R) 的调度决策, 存储O(M * R) (大约每对 map/reduce task 占用一个字节) 个状态在内存中.
R 大小一般被用户所限制, 一般通过调节 input data 大小(16M -> 64M) 确定 M 的大小, 以便上面描述的位置优化最佳有效.
Backup Tasks
一个经常导致整个 MapReduce 操作的原因是一个 “掉队者”(“straggler”): 一台机器花费异于寻常的时间完成最后的一些任务. 很多原因导致这种情况, 例如磁盘错误, 机器已经有许多其他任务, bug等等.
一个解决 “straggler” 问题的方式是, 在 MapReduce 操作快完成时, master 调度备用的进程执行剩下的任务, 无论备用还是原来的进程完成任务, 都标记任务完成. 通过这个机制可以显著提高大型 MapReduce 操作的完成时间, 而计算资源只增加了几个百分点.
Refinements
Partitioning Function
默认 partitioning function 是 hash(key) % R.
有时定制 partitioning function 是非常有用, 比如输出结果 key 是 url, 想相同 host 的 url 输出到同一个文件中, 那么使用 host(Hostname(urlkey)) mod R
Ordering Guarantees
在每个分区(partition), 中间 key/value 对按照key递增顺序处理, 从而保证每个分区结果也是一个顺序的输出文件.
Combiner Function
Combiner function 用于本机上做局部的合并操作在它发送给网络上之前. 用于加速整个 MapReduce 过程.
例如词频统计中, map task 任务产生大量的 <the, 1> 记录, combiner function 可以对这些记录做合并<the, n>.
Input and Output Types
MapReduce Lib 提供几种不同格式的读取和输出支持, 用户也可以自己实现对应的接口.
Side-effects
?
Skipping Bad Records
如果忽略一些记录是可接受的, MapReduce library 提供一个可选的执行模式, 跳过这些记录, 继续运行.
每个 worker 安装捕获 segmentation violations 和 bus errors 信号的处理, 用户代码产生信号是信号处理給 master 发送一个序列号, master存储它, 如果一条特定的记录发送超过一次的错误, 那么就跳过.
Local Execution
为了帮助用户 debugging, profiling, 和小规模 testing, MapReduce library 提供本地机器顺序执行所有任务的方式, 控制执行指定 map task, 通过一些指定的标记, 可以方便的使用任意的 debugging or testing 工具(gdb).
Status Information
通过 http 服务 master 查看整个MapReduce 操作过程中的状态信息.
Counter
MapReduce 提供 counter 设备为各种出现的事件.
用户可以创建 counter object, 例如:
Counter* uppercase;
uppercase = GetCounter("uppercase");
map(String name, String contents):
for each word w in contents:
if (isCapitalized(w)):
uppercase->Increment();
EmitIntermediate(w, "1");
每个机器上 counter 的值传 master, master 进行聚合, 同时去除重新执行任务的影响. 这些信息可以在 master 的 status page 上查看.
MapReduce library 提供默认的 counter 值, 如: 输入 k/v 对数量, 和输出的 k/v 对数量.
Lecture: Introduction
主题
课程是关于应用程序的基础设施, 和用抽象隐藏应用程序中分布式的复杂性.
主要三种抽象:
- 存储(storage)
- 通讯(communicatio)
- 计算(computation)
主题: 实现(Implementation)
RPC, threads, concurrency control.
主题: 性能(Performance)
- 理想: n倍的 servers -> n 倍的 throughput 提升
- N 越大拓展性越难提升(Scaling gets harder as N grows):
- 负载不均衡, 掉队者(stragglers).
- 非并行话的代码: initialization, interaction
- 共享资源瓶颈, 如网络
主题: 错误容忍(Fault tolerance)
1000s of servers, complex net -> always something broken
隐藏这些错误对应用程序.
目标:
- 可用性(Availability), 数据可用及时发生失败.
- 持久性(Durability), 错误修复后, 数据恢复正常.
复制服务(replicated servers): 一个服务挂了, 其他服务提供服务.
主题: 一致性(Consistency)
通用目的是基础设施有良好定义(well-defined)的行为, 如 “Get(k) 返回最新 Put(k, v) 的值”
困难:
- 复制的服务很难保持完全相同(identical).
- 客户端可能在多部操作中间崩溃.
- 服务不恰当时刻崩溃, 如执行之后回复之前.
- 网络波动可能让服务仿佛已经死了; risk of “split brain”.
一致性和性能不可兼得:
- 一致性需要通讯, 强一致性导致缓慢的系统.
- 高性能通常迫使系统为弱一致性
MapReduce
- 隐藏痛苦的细节:
- 启动软件在服务器
- 追踪任务
- 数据移动
- 错误恢复
-
拓展性良好(scales well):
- N 台机器 N 倍性能: 假设 M + R >= N, map task 是并行的, 它们之间没有依赖, reduce task 也一样
- 所以买机器就好了
-
什么限制性能:
- 2004年时, 作者认为是网络带宽(network cross-section bandwidth), data from map -> reduce.
- 最小化数据移动在网络中.
-
怎样减少 slow network 的影响:
- Map task 读取 GFS 上的本地副本.
- Intermediate data 传输只有一次.
- Big network transfers are more efficient.
-
怎样取得好的负载均衡:
- 关键是 scaling , 不要让 N - 1 个服务等待一个结束.
- 总会一些任务花费的时间比较长, 解决方式: tasks 数量 » workers 数量.
-
关于错误容忍:
- 隐藏错误是极大简化程序.
-
MR仅仅程序运行 map/reduce tasks, MR 需要 map/reduce 是 pure functions, 这个也是对比其他平行系统的主要限制, 也是 MR 简单明了的关键.
-
worker crash 恢复细节: 看前面论文笔记
-
其他一些错误细节:
-
如果master 给两个 worker 相同 map task?
master 将只会告诉 reduce task 其中一个.
-
如果master 给两个 worker 相同 reduce task?
它们先同时写入 2 个临时文件, GFS 通过保证原子重命名文件保证它们不会混乱, 其中一个将可见.
-
某个 worker 非常慢, a “straggler”?
看前面论文 backeup tasks
-
如果 worker 机器错误的结果, 由于软件或硬件中断(due to broken h/w or s/w)
too bad! MR assumes “fail-stop” CPUs and software.
-
-
那些应用不适合用 MapReduce?
- 不是所有的适合 map/shuffle/reduce 模式.
- 小数据, 消耗太大.
- 少量更新在大数据集, 如添加一些文档到一个大索引上.
- 不可预测的读
- Multiple shuffles, e.g. page-rank
-
总结
- 不是最高效(efficient) 或 灵活(flexible) 的
- Scales well.
- Easy to program – failures and data movement are hidden.
These were good trade-offs in practice
